
NLG in conversational AI: The challenges of generating language
May 26, 2022

This blog is by Agape Deng, Senior Computational Linguist
“Siri, where does Santa live?”
“He’s in your heart and at The North Pole. Mostly at the North Pole,” comes the tart, prompt reply from Apple’s famous digital assistant.
Technologies like Siri rely on machine learning, big data, and natural language processing (NLP) to respond to human requests in a sensible, helpful, and sometimes playful way. Because they are designed to mimic natural human dialogue, they are often referred to as dialogue systems, or conversational AI.
Though digital assistants may appear to have different personalities, most of them share certain similar components that work together to make conversation possible.
In this blog post, we will briefly skim each component’s role in a classic, goal-oriented dialogue system before diving into the particular challenges that the natural language generation (NLG) component faces.
Components of a goal-oriented dialogue system
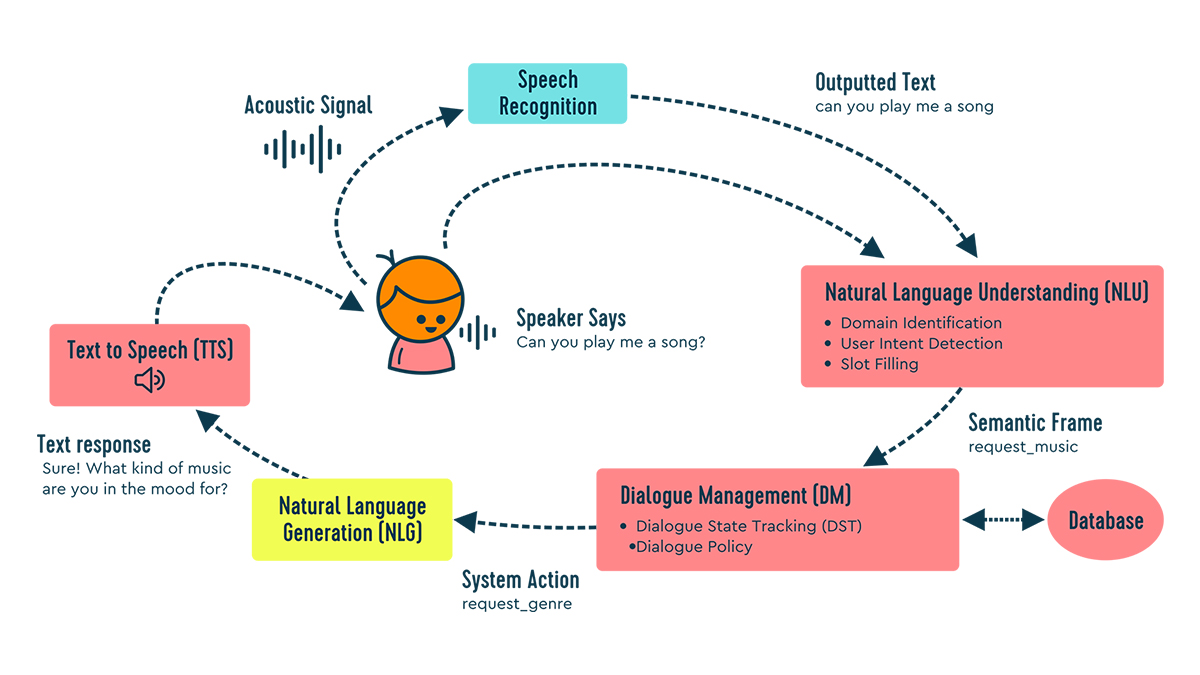
Automatic speech recognition (ASR)
When a user utters a request to a conversational agent as in the image above, “Can you play me a song?” the acoustic signal first goes to the automatic speech recognition (ASR) module and is converted to text. It is imperative that this module achieves a high level of accuracy as it affects all downstream tasks and, ultimately, the ability for the system to respond appropriately.
At SoapBox Labs, our speech technology is tailored to children’s voices, and with the help of custom language models, can achieve a best-in-class accuracy on par with humans for kids of all ages, accents, and dialects.
Natural language understanding (NLU)
The text from the ASR module is then fed to the NLU module, where the user’s intent and crucial bits of detail, such as date and genre, are extracted into a formal, logical representation that the system can use. (You can read more on this on our blog on intent recognition.)
In the diagram example, the intent is request_music. This formal representation of the user intent is next fed to the dialogue manager.
Dialogue management (DM)
The DM is the “brain” component of a dialogue system that decides what the system should do or say in response. It outputs the system’s action in the form of a logical representation, which becomes the input to the NLG module.
In this case, the DM has decided that the best next action is to request that the user specify a genre of music. Oftentimes, the DM may query a database to provide knowledge-based responses.
Natural language generation (NLG)
This module is responsible for converting the DM’s formally represented action into human-friendly, well-formed, grammatical sentences. For example, if the system’s action were to recommend a song, the NLG component might take the logical form such as the below and generate sentences such as 1 and 2.
recommend(song name= Twinkle, Twinkle, Little Star, genre= lullaby)
1. How about the lullaby Twinkle, Twinkle, Little Star?
2. Would you like to hear the Twinkle, Twinkle, Little Star lullaby?
Text to speech (TTS)
Finally, if the dialogue system is a spoken one, where voice is the medium for interaction, the generated text is sent to a TTS module where it is rendered in a life-like voice that aligns with the brand’s image and use case.
The challenge for NLG
Your own experience would confirm that generating language is a cognitively more difficult task than understanding the same. Babies can understand words long before they are able to speak them. Multiple choice questions are easier than open questions that require written responses. Difficult mathematical concepts have to be understood before you can explain them to others. These all highlight the difference between what psychologists call recognition versus recall tasks. Advancements in deep neural nets have lent themselves well to solving recognition tasks such as ASR and NLU; but their effects on recall tasks such as NLG, especially in industrial applications, are still limited.
“Wait a minute,” the astute reader might say. “What about GPT-2 and 3, the ‘chameleon-like’ transformer models that can generate coherent texts, pen poems, and wax philosophical?”
While it is true that the release of GPT-2 in 2019 marked a breakthrough for NLG and has been used to great effect in building chatbots with personas and humor, there are a number of reasons why they are not often employed in industrial applications.
High stakes
The biggest reason is perhaps the fact that businesses, with their reputations and clients at stake, require high precision and control over the output of their digital agents. End-users largely form their impression of an entire system based on the NLG output because it has the highest visibility. Thus, companies cannot risk non-deterministic outputs that could potentially be ungrammatical, non-compliant, non-sequitur, or offensive. For this reason, models like GPT lend themselves better to entertainment chatbots where conversations can be meandering and users are more forgiving, compared to task-oriented dialogue agents where every turn must contribute to a user’s end goal.
Another, rather obvious reason is that the current approach of using hand-crafted, rule-based templates is hard to beat in terms of precision and reliability. When the domain is limited and clearly defined, templates provide adequate coverage, are easy to develop, and can be exhaustively tested, ensuring quality and compliance. For most companies, reliability is paramount; thus, despite their drawbacks of inflexibility, difficulty in scaling, and lack of lexical variability, they are still preferred in business applications over state-of-art, deep learning approaches, as the latter presents a point of risk.
Conclusion
Today, with the availability of developing options, from leading commercial cloud offerings like Google’s Dialogflow to open-source solutions like RASA and botpress, bringing a dialogue system to production is easier than ever before. Many of these solutions provide all the basic components of a dialogue system out of the box but also offer the flexibility to integrate custom models via an API, giving developers more control over the architecture of the system.
Developers may want to plug in their own or third-party components if the native components do not support a certain language or if they want the system to perform well for a specific demographic. For example, a dialogue system designed for children could benefit from an ASR model that was custom-built for kids, such as the ones built at SoapBox Labs. Achieving higher accuracy from the get-go ensures that the rest of the system can flow seamlessly.
Want to learn more about SoapBox Labs?
Explore our resources for white papers, guides, and use case videos on our voice technology for kids, or email us at hello@soapboxlabs.com.
Share this
Related
