
Part 3: Voice-First Experiences for Kids
August 5, 2021

Contents
From working closely with our clients, SoapBox’s Head of UX Declan Moore and Senior Software Engineer Ronan Tumelty have helped craft compelling and constructive voice experiences for kids.
In Part 1 of our Beginner’s Guide, Declan and Ronan looked at the use of visual cues to support voice interactions. In Part 2 they focused on the cues and triggers that can be used to determine when a user is starting or ending an interaction.
Now in Part 3, Declan and Ronan examine some principles of scoring and how to interpret and use scores as user-facing feedback in a voice-driven experience.
An Overview
Providing feedback to a young user, whether in a game or an educational scenario, can be tricky at the best of times. Correct and meaningful feedback is integral to offering encouragement to a child who is finding your voice-enabled experience challenging.
In this article, we will examine some principles of scoring and how to interpret and use them as feedback to users as part of a voice-driven experience.
Terms Used
To get us started, let’s look at some definitions:
Scoring: Scoring, as discussed here, is the collection of data points and information the SoapBox Voice Engine provides to you.
Feedback: This is the user-facing content or UI response that your product shows to the end user. One example would be a graphical representation of your interpretation of the score.
Predictions: A decision made by an algorithm, frequently accompanied with a confidence score.
Voice Experiences and Scoring
Central to the output of SoapBox Engine is the concept of a “score”. Let’s take a look at what we mean by that and how to best make use of this in your voice-driven experiences.
Confidence vs correctness
In traditional education, a “score” assigned to a student’s answer is generally considered to be a measure of the “correctness” of the answer. How exactly this is determined differs with the subject matter, as some subjects are more open to interpretation than others.
The same scoring logic — a score of 100% is the most correct, while a score of 50% is “half right” — cannot be applied to the output of machine learning systems, however. In a voice-driven scenario, we have to think about these values differently to more traditional scoring.
Rather than representing how correct the source data is, in our speech recognition system, a score — often called a confidence score — is a measure of how confident the system is in its prediction of what a user said.
Typically, confidence scores are returned as a value between 0 and 1, or scaled to a percentage. A score of 0.5 (50%) is the tipping point of the confidence curve. At this point, the system believes it is more likely than not to have correctly interpreted the source data. The higher the confidence level, the more sure the system is of its prediction; the lower it is, the less certain.
Let’s translate some confidence scores to equivalent statements a person might say if they were making the judgement call:

At SoapBox Labs, we’ve collected data from 193 countries, across a broad age range, and across a huge diversity of accents and dialects. This, along with our rigorous evaluation process, allows us to create speech solutions that perform well even with more unique accents or very young children.
Confidence thresholds
A threshold is a value of confidence over which a prediction is accepted. It can be used to determine how to interpret the confidence scores provided.
Choosing a threshold value
So how do you decide what your threshold should be?
Start in the middle
The most intuitive value to choose for a threshold would be 0.5 (or 50%), as in the above example. As discussed earlier, this is the point at which the speech recognition system is more certain about its prediction than it is uncertain.
Let’s assign a threshold of 50% to our example sentence from Part 1:
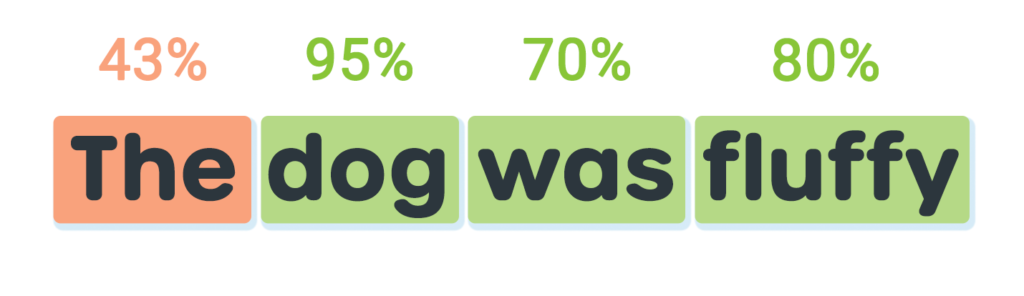
As you can see, by assigning a threshold of 50%, we have separated the sentence into words that we are confident of (in green), and those that did not meet our requirements (orange).
In many use cases, this is sufficient and is a good starting point. But it may not suit all cases. So let’s look at a situation where we might choose to change that threshold and the effect it may have.
When to use a lower threshold
By lowering the threshold, we make the speech recognition system more lenient and increase the likelihood of accepting as “correct” or “true” predictions that may otherwise have been rejected.
This increased acceptance comes with a trade-off, however: the more accepting a system is, the more likely incorrect predictions will be accepted as correct. An extreme example of this would be a threshold of 0%, whereby the system would accept all predictions as correct!
If it’s more important that the voice experience you’re delivering responds to correct predictions than it allows some incorrect predictions through, choosing a lower threshold may make sense. This is generally the case in low-stakes scenarios (for example, in educational products for very young children where encouragement is as, if not more, important than precision). In that case, letting some incorrect answers through is probably acceptable.
Here are some example use cases where you may want to use a lower threshold:
- Play/entertainment experiences
- Practice scenarios
- Voice commands or confirmations
- Very young or non-native users
When to use a higher threshold
Increasing the threshold increases the precision of the speech recognition system so that it will be more likely to only accept correct predictions. Like choosing a lower threshold, choosing a higher threshold comes with a trade-off, in that the system may reject some correct predictions. At a threshold of 100%, the system will only ever accept predictions that receive a score of 100% (a very rare occurrence), and discard most correct predictions.
Increased precision is valuable in situations where you only want the system to respond when it has a high degree of confidence that it has correctly interpreted the user. Examples of this would include formal assessments where the outcome of the interaction has an effect on a student’s grade or when it affects the user’s next move in a game.
Here are some example use cases where you may want to use a higher threshold:
- Reading assessments
- Vocabulary practice
- Pronunciation assessments
Multiple thresholds
There is no reason to limit yourself to just one threshold. By having two or even more thresholds in an interaction, you can add nuance to your responses to a user.
Let’s look again at our sentence from earlier but with “fluffy” scoring only 20%.
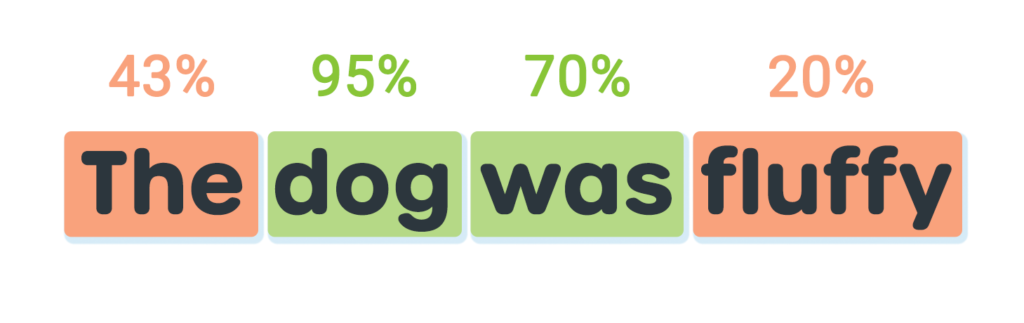
With just the acceptance threshold of 50% in place, both “The” and “fluffy” are highlighted in orange. However, as 43% is quite close to our acceptance threshold, we may want to treat it more favorably. Let’s introduce a second threshold at 30%:
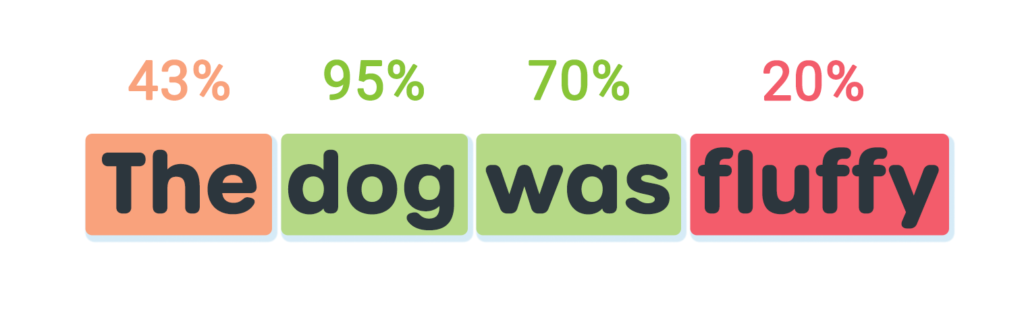
There is now a clear distinction between the word we weren’t quite sure about, and one we’re pretty sure isn’t a match. This allows us to give more useful feedback to a user. We will go into a bit more detail on this below.
This is not the only way you could apply multiple thresholds to your voice-enabled experiences. Another possible use case would be a conversational experience in which a child is interacting with a toy or digital character. When faced with an uncertain confidence score in this scenario, you may decide to ask the user to confirm that the system understood them before responding.
For example, if the toy asked a child “What is your favorite fruit?”, and their response predicted both “lemon” and “melon” with middling confidence, the toy could ask a follow-up question: “I think you said lemon, is that correct?” Once you have received confirmation from the user (or the opposite), you can make an informed choice on how to proceed.
You could also apply this approach in formal assessment, where you want to avoid marking an answer incorrectly. To offset this, you could use thresholds to highlight areas of an answer that the system is less confident in for review by a teacher. This would enable them to make better use of their time, freeing them up to intervene with students who may be struggling.
Experimentation
As seen, your choices of thresholds are very important to making your voice experience the best it can be. Even within the same product, different situations may demand different requirements, and by extension, different thresholds. As always, the best way to determine what’s best for your users is to first decide what the objective of your voice experience is for your users, and then to experiment and validate it from there!
Feeding Back to the User
So we have a score back from the speech recognition system, and we’ve identified what thresholds work for our product. How might that translate into user-facing feedback?
This is hugely dependent on your use case. You may not wish to provide any score-based feedback in a formal assessment scenario, for example. Likewise, feedback can take many forms. It could be scaffolded feedback for educational purposes, or it could be purely for fun, where you’re relying on gamification strategies like rewards or collectibles.
Example
For now, let’s revisit the feedback screen from our sample App in Part 1.

Let’s go through what’s happening here.
When the child read the sentence, we got confidence scores back from the SoapBox Engine for each word and for the sentence as a whole.
The confidence scores for each word were:
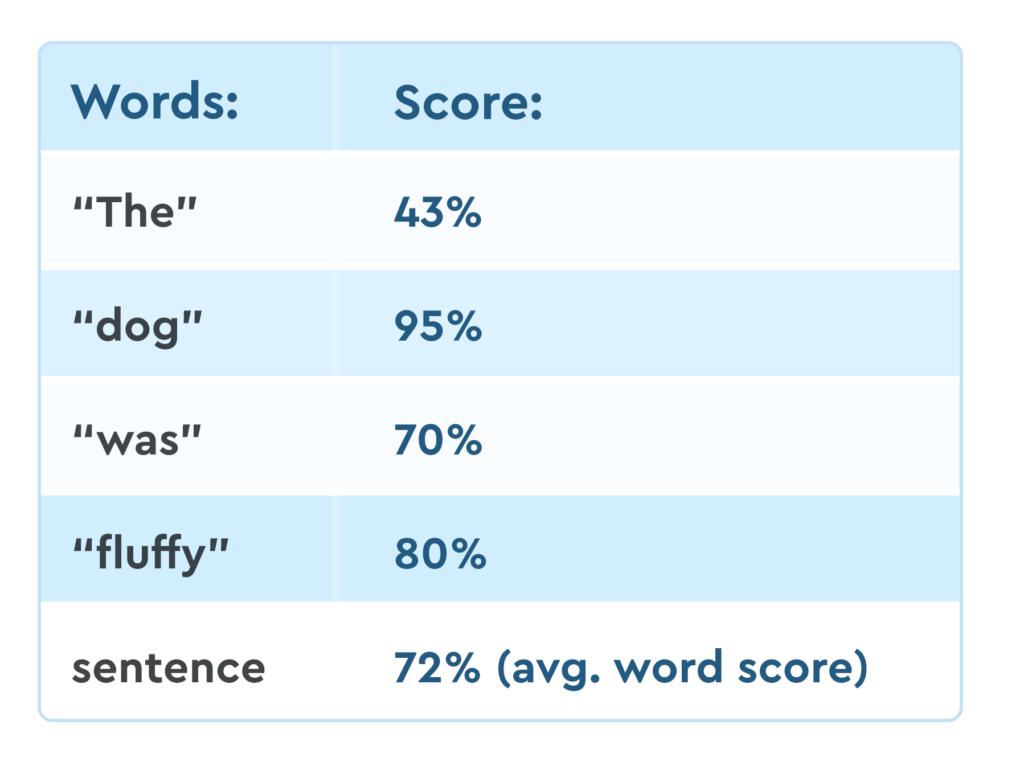
In this example, the product is an early literacy app. We’re focused on increasing a kid’s confidence when reading, and we want to encourage them to speak out loud. Our threshold choice should reflect this.
The words “dog”, “was”, and “fluffy” all scored 70%+ for this reading. For this App, we’ll consider that “good”.
“The” scores 43%. This likely means that the child mispronounced “The”. However, as this is a practice scenario, we’re happy to consider this “good enough”.
We’re also choosing to score the overall sentence. Represented by the percentage UI in the top-right of the screen, this is calculated by averaging the individual word scores.
Additional feedback
We want to give the kid or their parents and teachers some indication that they have room to improve. So for this app, we’re dividing feedback into three broad threshold bands.

As “The” scored under 50%, we color it orange in the UI.
Since the sentence overall got 72%, we color that score green.
You don’t have to display the percentage of course. Alternative metaphors like “three stars” or a points system could work here too. The confidence score is data that can be displayed any way you want.
So what if they get something “wrong”?
In this case, we’ve defined any confidence score below 30% as incorrect, or at least something that we wish to give specific feedback on.
Let’s say the kid got a score of 20% for “fluffy”, we would then need to decide how the app handles that.
If the word scored that low, it’s likely they said something entirely different.
The sentence would get an overall score of 57%. This is a lower score than the previous example, but for our use case, it’s still considered a “pass”. And the sentence gets a high enough score that we are happy to acknowledge it through UI feedback but take no further steps.

Whether we decided to do anything about the low scoring word is entirely down to the voice-enabled experience we’re building.
In different scenarios, we could decide to do any number of things:
- Give the kid the opportunity to retry the sentence.
- Ask them to repeat/practice “fluffy” on its own.
- Provide scaffolded feedback on “fluffy” and provide the correct pronunciation.
- Add “fluffy” to a “tricky word” list, and give them the opportunity to practice it at a later stage.
Final Notes
As you can see, how you use thresholds is highly dependent on your use case and the goals you’re trying to achieve within your voice experiences. The examples we’ve shared only scratch the surface, and auditory and visual feedback is only a fraction of what the potential feedback is, with areas like gamification and dynamic content strategies also playing huge roles.
Get in Touch
Voice experiences for kids are as varied as the approaches we take to tackling them. At SoapBox, we may be experts when it comes to speech recognition for kids, but we’re still at the beginning of an exciting journey of experimentation when it comes to voice-first experiences for kids, and we’d love to keep learning as we help you with yours.
All feedback, questions, and suggestions for future topics in this Beginner’s Guide series are welcome. If there is anything you would like us to cover, please get in touch: Hello@SoapBoxLabs.com.
