
An Introduction to MLOps: Benefits, Principles, and Applications
April 7, 2022
Contents
This blog is by Arnaud Letondor, Senior Software Engineer
Introduction
At SoapBox Labs, machine learning (ML) is at the core of our technology. All of our speech solutions rely, in one way or another, on ML models that are the result of hours of training. Experimenting with ML and producing models has been made easier over time with the emergence of new technologies and frameworks such as TensorFlow, Keras, Pytorch, and others.
But the journey of an ML model doesn’t stop once it has been trained, and deploying a model so that customers (or end-users) get meaningful insights from it is often challenging. Luckily, bridging that gap can be eased by the application of MLOps.
MLOps has become increasingly more popular over the last few years, and companies involved in ML have started investing in it. This is an area we are very interested in on the Engineering team at SoapBox Labs, and try to enforce in all our ML projects.
This blog is based on our research over the past several months and draws upon key sources we’ve found particularly helpful in learning about the emerging field of MLOps:
- Why You Might Want to Use Machine Learning (by INNOQ)
- MLOps Principles (by INNOQ)
- Introduction to Machine Learning in Production (by DeepLearning.AI)
In this blog we’ll cover:
- What is MLOps?
- Benefits of MLOps
- MLOps principles
- Machine learning project lifecycle
- Applications of MLOps
What is MLOps?
MLOps stands for machine learning operations. It is a set of practices that aim to deploy and maintain machine learning models in production reliably and efficiently.
The goal of applying MLOps, as defined by INNOQ, is “to provide an end-to-end machine learning development process to design, build, and manage reproducible, testable, and evolvable ML-powered software.”
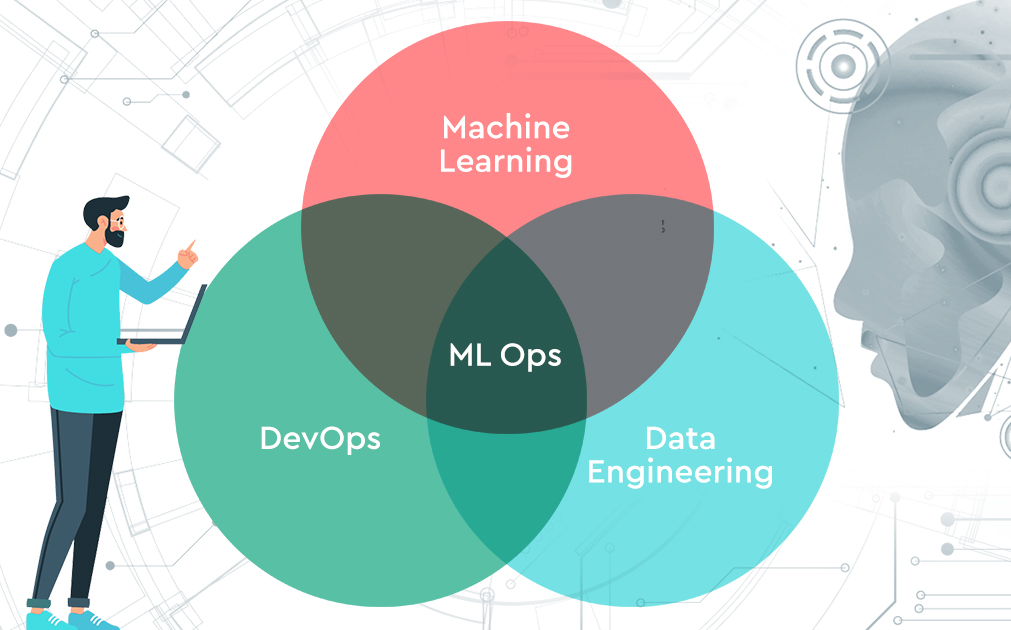
MLOps is a combination of three fields:
- Machine learning
- Data engineering
- DevOps
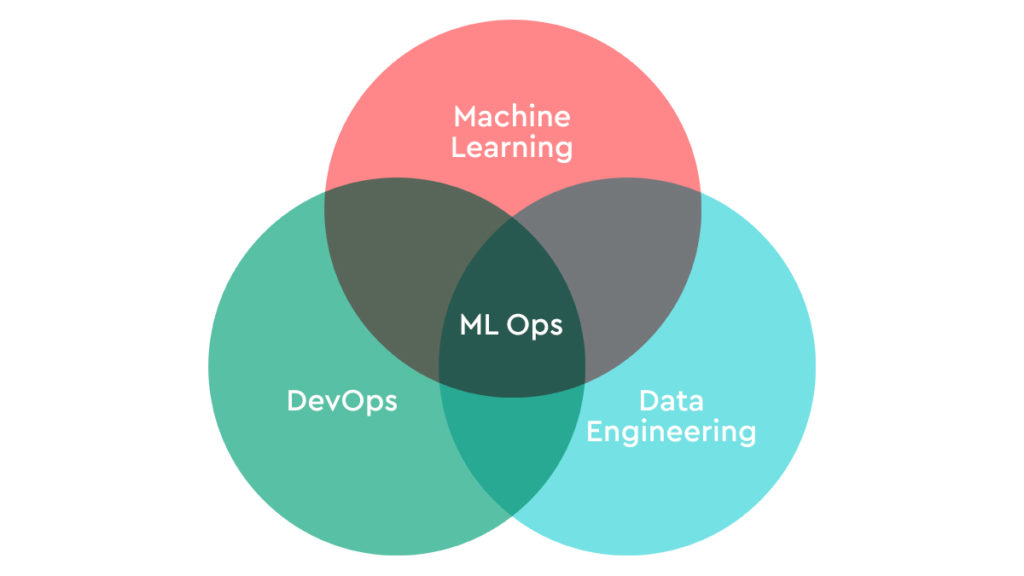
MLOps is to machine learning and data engineering what DevOps is to traditional software development.
Benefits of MLOps
Here are three key benefits of MLOps (a non-exhaustive list):
1. Bridging the gap between ML model development and practical deployments
Many companies have invested in machine learning in some way. According to a 2021 IBM report, about 80% of companies globally are using automation and AI technologies or planning to use them in the next year.
The 2021 Algorithmia (a specialist MLOps platform for businesses) report identifies a huge gap between the initial research phase where ML models are being trained and experimented with and the time they are deployed and used by customers and end users.
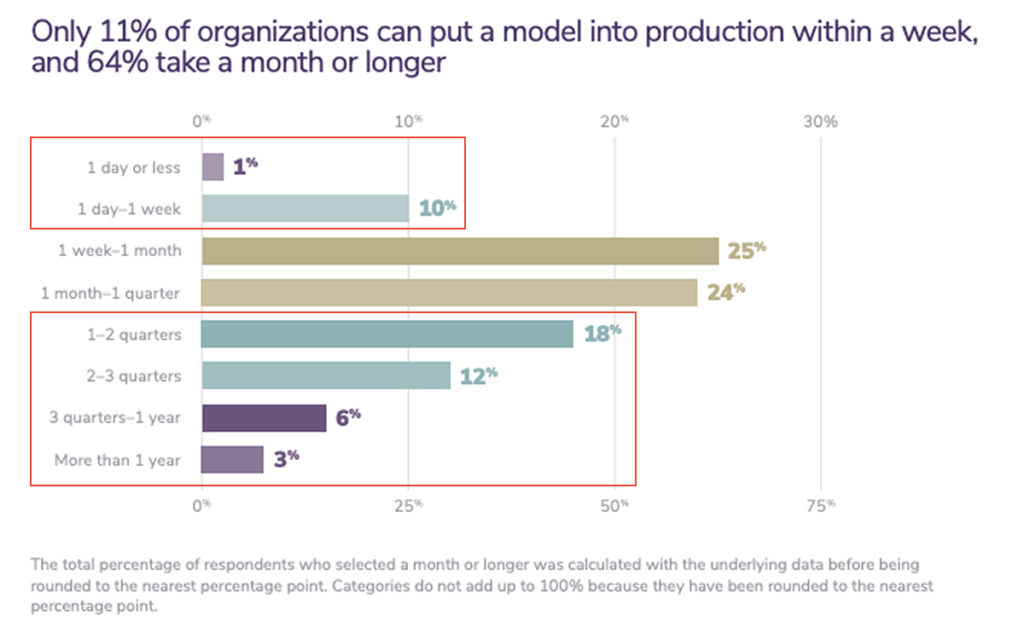
Of the organizations surveyed in the report, only 11% are deploying models in a week or less. Meanwhile, about 64% of companies are taking a month, if not longer, to deploy a model.
Importantly, the time spent on deployment is not spent in other areas, such as research or development.
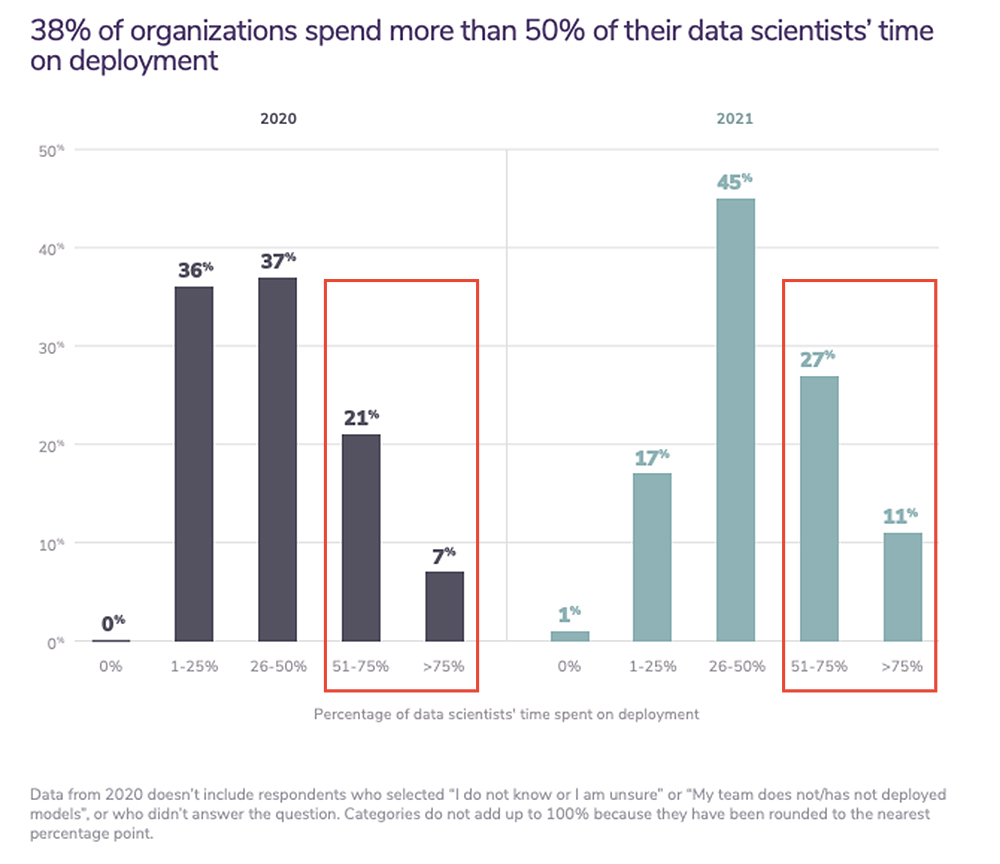
Another interesting trend from Algorithmia’s report shows that the amount of data scientists’ time spent on deployment increased from 2020 to 2021. Thirty-eight percent of organizations spent more than 50% of their data scientists’ time on deployment in 2021, an increase of 10 percentage points from 2020.
That’s one of the critical issues MLOps is hoping to solve: reducing the amount of time spent on deploying a model.
That gap between development and deployment is primarily explained by the fundamental difference between traditional software and ML-powered solutions. ML-powered solutions are more complex because they’re made up of three moving components:
- Data
- Machine learning model
- Code that’s meant to execute that model
Generally, changing one of those three components affects one, if not two, of the other components. That’s why when dealing with those three as a block, it can become problematic to then make changes to an ML solution.
Also, the deployment of ML solutions can be done on different types of platforms. Deploying on a server is very different from deploying on, say, a mobile phone or embedded device.
2. Enabling fast experimenting, efficient data preparation and model training, and proper testing.
MLOps doesn’t only apply to the deployment of a given ML model. It can also impact the earlier stages of the model development. Producing a model takes time and computing resources.
In order to produce a model, a dedicated team of ML engineers and data scientists needs to:
- Prepare data that will be used to train and evaluate the model.
- Train and evaluate that model using the previously prepared data.
- Run several experiments with various hyperparameter combinations to see which leads to the best results.
These processes can be facilitated with MLOps and, therefore, increase the team’s efficiency.
3. Monitoring performances of models already deployed to prevent model decay
A third benefit of MLOps is to be able to quickly react if / when a model behaves abnormally. This is enabled by the monitoring of the model predictions so that we can track how it performs over time and prevent model decay (i.e., model performing worse over time) and bias (i.e., predictions that are skewed towards or against a particular outcome).
By monitoring the performance of models in production, we can more easily detect when they behave abnormally (i.e., predict inaccurately) and therefore react (e.g., by adjusting our training data) accordingly. In the context of speech recognition, this can help identify accent bias or sounds our model struggles to recognize, for instance.
MLOps principles
Now that we’ve established the pain points that MLOps aims to solve, let’s review its five core principles. (Again, this is a non-exhaustive list, but these ones stood out to us based on our research and development pipelines.)
- Versioning: Recording and versioning all assets in the machine learning pipeline — code, models, datasets used for model training, etc.
- Testing: Code testing, model evaluation, and ML infrastructure and pipeline tests.
- Automation: Increasing the velocity and reliability of deployment by automating ML processes.
- Reproducibility: In ML projects, it’s important to consistently get the same results over time. When running the same pipelines, you expect to see similar results from run one to run two, so that there is no unpredictability.
- Monitoring: Once the model has been deployed, it needs to be monitored to ensure that it’s performing as expected over time. If it’s not, the model must be retrained or changed.
ML project lifecycle
Before examining how we apply MLOps in our speech recognition technology at SoapBox, let’s take a step back and review the lifecycle of a machine learning project.
The following five-stage cycle is based on a Coursera course. The course refers to a four-stage cycle, but we think it’s clearer to add an extra “Application” phase prior to “Deployment”.

Each stage of the ML lifecycle results in one or more artifacts, which need to be isolated, so that the project remains flexible and modular and isn’t treated as a block. This makes it easier to manage the different aspects of an ML project — whether it be data, the model, etc.
1. Scoping

Scoping involves deciding on:
- The end solution
- The platform the end solution will be deployed on
- Deciding on your key metrics (e.g., accuracy, latency, throughput)
- Hardware requirements (e.g., RAM, storage, CPU frequency)
Output: Design documentation recording all key decisions
2. Data

The Data phase is the first of the machine learning-oriented stages. It involves:
- Identifying and establishing data sources.
- Labeling and organizing data (training, evaluation, and validation datasets)
Output: Prepared dataset(s)
3. Modeling

Modeling is the third stage of the ML project lifecycle. It involves:
- Establishing the feature type and dimensions to input to the model.
- Defining and training a model (choosing an ML algorithm and technology for training that model, establishing the model output type and dimension, and fine tuning hyperparameters)
- Evaluating the model after training based on the key metrics that were established in the Scoping phase (e.g., accuracy and latency) to make adjustments if needed.
Output: Trained and evaluated model (it should be versioned and separated from the data or your application code)
4. Application

The application stage is about building the end application and integrating it with the previously trained model.
The first thing to ensure when integrating the model into an application is that you can produce the same type of features used for training in your application, so that the model can run predictions based on the same input it was trained on.
If we take the example of a keyword spotter that is trained to recognize “yes” or “no” based on a one-second audio clip represented as mel-frequency Cepstral Coefficients (MFCCs) and we instead feed our application model mel-spectrograms, our model will not perform well (if work at all!).
Similarly, the model output has to be interpreted by the application code so it can be translated into something that is meaningful to the end-user.
Finally, a series of tests can be performed at this stage to measure the model’s performance within the application:
- From an accuracy point of view, this ensures similar accuracy to what was observed during the model evaluation.
- From a latency point of view, this compares it to what was initially defined during scoping.
Output: Application executable, environment, versioned code
5. Deployment

Deployment is the final stage of the MLOps life cycle. This is when the application is brought to production.
Once the application is deployed, you still have to monitor and maintain the system to ensure that the model performance doesn’t degrade over time, and retrain it if it does by changing the data or another element in the pipeline.
Output: Deployed application and deployment templates (which also can be versioned)
Application of MLOps
Now that we’ve seen a high-level overview of the machine-learning product lifecycle, we can better understand where to apply our five MLOps principles to facilitate each phase and make them more efficient.
In the following table, each MLOps principle is mapped to the machine learning lifecycle stages. We’ve also included common technologies used at each stage.
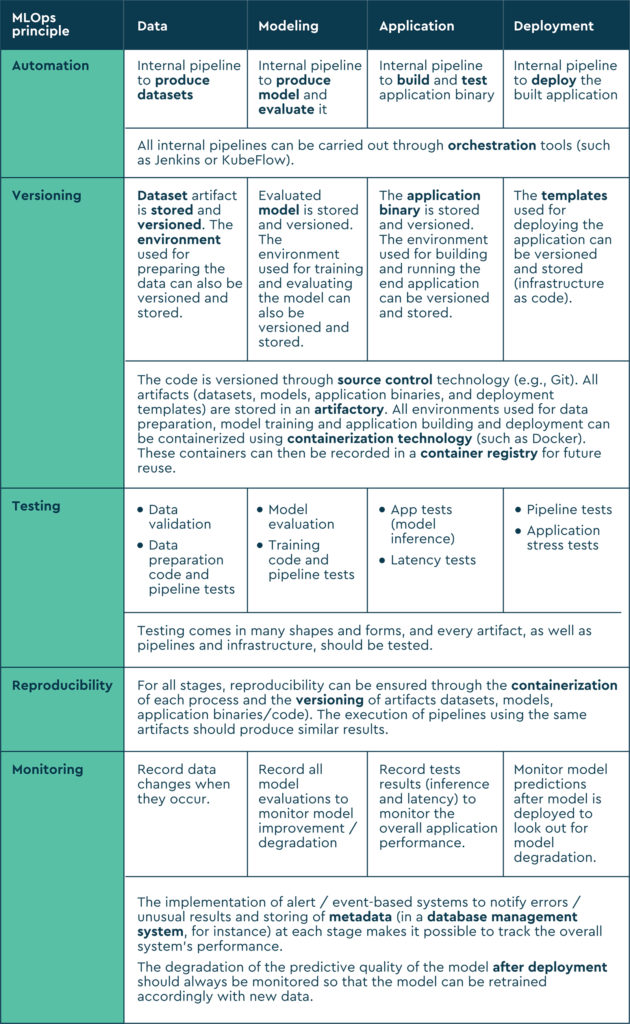
Conclusions and takeaways
Here’s a recap of what we’ve covered:
- MLOps is a set of principles to facilitate machine learning powered software deployment.
- MLOps is a combination of data engineering, machine learning, and DevOps.
- Five of the main MLOps principles are: versioning, testing, automation, reproducibility and monitoring.
- The lifecycle of ML projects can be divided into five main stages: scoping, data engineering, modeling, application, and deployment. Each stage produces at least one artifact.
- The data engineering, modeling, application and deployment stages can be automated by the introduction of dedicated pipelines that can be executed in the internal infrastructure.
This only scratches the surface of the world of MLOps — there’s so much more to it! I highly recommend that you check out the resources linked throughout this blog:
- Why You Might Want to Use Machine Learning (by INNOQ)
- MLOps Principles (by INNOQ)
- Introduction to Machine Learning in Production (by DeepLearning.AI)
Want to learn more about SoapBox?
Visit The SoapBox Tech Blog for the latest articles and stories from our Speech Tech, Engineering, and Product teams on how our voice engine works and tips and tricks for designing voice experiences for kids.
Also, explore our website for use case videos, more about our technology and company, and many more additional resources aimed at helping and educating our audience.
Share this
Related
